
“What on earth is that?!” I thought to myself when we were presented with our latest Code-a-thon challenge on Monday morning. As you may well be able to see from the header image, the test before us was a difficult one: columns, colours, glosses, handwriting and marginalia (that even had its own marginalia!). How could all of this be encoded without becoming lost in a swamp of messy Latin script? I decided that the best way to even begin approaching the problem was to keep things simple. By focusing on the core part of the text, a fragment from Isaiah 38, I thought it might be possible to bring some clarity to a small portion of the chaos.
In the sixty-minute time slot that we had available, the other interns chose to wrestle with the complex array of marginalia. Feeling less confident, the first step I took was instead to add some extra details to the base code that we had been given by our mentors Sebastian Dows-Miller and Mary Newman. One of these was the inclusion of the decorated initials which are colourfully marked in the original manuscript. Aside from the obvious benefit of looking pretty, they also have the advantage of visually signalling to the reader when a new sentence begins, something that is particularly useful when working with the overlapping scrawls of medieval scribes. The next thing to add was speech markers. Although speech is not punctuated differently to narrative prose in the Isaiah passage, I decided to differentiate between prose and speech by deploying the <q> element
in order to clarify the text for a modern reader. As some readers might not have a good historical knowledge of the Bible, I also chose to mark proper nouns and provide links to their wikidata pages in the TEI header. Usefully, these defined names and places could also be referred back to in the main body of the encoding, meaning that the bits of speech could be linked to the people that said them. With these added features, my code began to look a little chaotic itself by the end of the session:

Having recovered from Monday’s brain-stretching Code-a-thon, Wednesday saw us embark on another digital adventure, this time to the impressive Upper Library at Queen’s College for a second viewing of our volume of pamphlets (available online here). OCC Head of Conservation and Preservation Jane Eagan, accompanied by Matthew Shaw, gave us some new insight into the structure and history behind the volume of texts that we have been working to encode.

In her presentation, Jane explained that the current binding that the pamphlets are grouped in is made of sheepskin and likely originates from the 19th century, though there are repairs from the late 19th / early 20th century that have been made to the volume as well. The differing levels of grime, dirt and water damage across the pamphlets also suggest that each of the texts originally had a life of its own before being grouped into the Sammelband as it currently stands, with some having been left unbound in the open and others more carefully looked after. Much to my own surprise, we learnt that the pamphlets had been stitched together. This was a common way of binding books, though I was personally still shocked that librarians of the past were happy to put their precious texts through such an intense form of book surgery, literally puncturing them with needles. Without this procedure though, they may not have made it to the present day for us to digitise.
Both the Code-a-thon and library presentation provided a useful background as I began to think about clarity and chaos in relation to my own project aimed at creating a digital edition of a short text titled ‘An A.B.C. for chyldren’. In week 3, I had concentrated on producing a diplomatic transcription and encoding of the text that might be helpful for linguists and other scholars interested in the history of the English language and English education. In week 4, however, my aim was to start encoding a version of the text that could be read (with some guidance from their teachers) by the school pupils of today, helping the pamphlet to regain some of its original pedagogical purpose. This would be quite a challenge, especially given the many complexities of the ABC, ranging from bits of questionable Latin to abbreviations that modern adult English speakers, let alone schoolchildren, would find difficult to interpret. There was also an important balance to strike: although I wanted youngsters to be able to consume the text, it also seemed vital that it kept its authentic Tudor flavour.
This all meant that some sort of compromise was in order. Obsolete characters like long ‘s’ and ‘r’ rotunda got the chop, soon followed by abbreviations such as the Tironian note or macrons above vowels that might alienate younger readers. The passages of Latin that dominate the latter part of ‘An A.B.C. for chyldren’ were given translations where they did not already have them. At the same time though, I tried to maintain a good level of 16th century spice by adding explanatory footnotes to archaic or technical vocabulary such as ‘diphthong’ or ‘orthography’ rather than simply dispensing with them and rewording the passages they came from. All these changes have culminated in an edition that will hopefully provide an engaging challenge for school pupils, one that can make them think without burning them out.
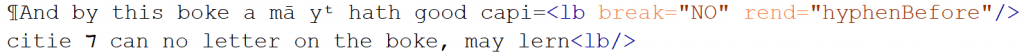

With two (almost) completed versions of the ABC pamphlet and week 4 of the UNIQ+ internship at its end, the next and final step of our programme is to prepare for another new experience: presenting at week 5’s virtual academic conference.
Robbie Spiers is one of this year’s interns with the History of the Book. He studied Modern and Medieval Languages at the University of Cambridge and is hoping to pursue a career in academia in the future.