
By Tianyi Liu (MSt in Modern Languages)
On 8 November 2023, as a prelude to the launch of the e-ilustrace database of early printed Czech books (https://e-ilustrace.cz/en/), Dr Giles Bergel treated the History of the Book class to a fascinating session on image matching technology. Giles Bergel trained as book historian and now works in the Faculty of Engineering on image comparison software. Thanks to his presentation about how image searching and matching applied in book illustration, we gained a better understanding on how the technology works in the field of digital humanities.
To start the session, we had some fun playing a spot-the-difference game manually comparing woodcuts from different editions showing the beasts polemically called ‘pope-donkey’ and ‘monk-calf’ by Martin Luther. These gave us a taste of what image matching was.

Henrike Lähnemann then introduced Taylor Editions to us in order to help us thinking about our project next term. Taylor editions is a way of encoding historical text that makes it possible to link it with the original images and make it accessible through translation, standardization and audio recordings, etc. One example of this is the encoding of German, French, and English versions of the monk calf text done by three Master students in 2022/23, combined with an exhibition on early modern monsters in the Taylorian.

This pamphlet was firstly published in German in 1523, translated into Latin in 1546, from there into French in 1557 and via this into English in 1579. Thanks to an library hunting expedition by two research interns working with Henrike Lähnemann, Kira Kohlgrüber and Karen Wenzel, and the help of a large number of College librarians, we were able to see photographs of two later editions of the Latin text (1551 and 1562) from the Complete Works of Martin Luther in various College Libraries such as Balliol, Jesus, Magdalen, Queen’s and Worcester.






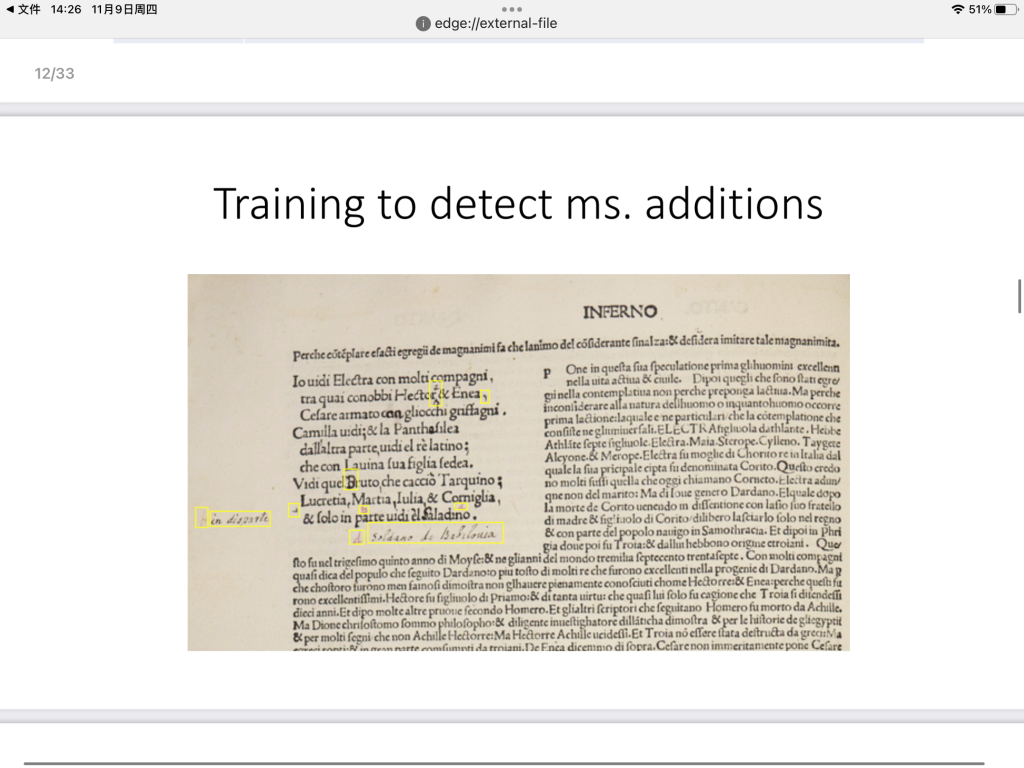
In the second part of the session, Giles Bergel introduced us his research on image matching in the Visual Geometry Group. They trained the machine to detect illustrations which works remarkably well even if sometimes the machine comes up with false positives by detecting a printed offset, a provenance stamp, a dog ear, or handwritten notes rather than illustrations.


This technology can also be used to detect additions and predict text and commentary. It can distinguish the original text from notes and commentary, and in this way researchers can answer some questions like “What are the most intensely commented parts of the texts?” and “How do the affordances of print impose themselves on the text(s)?”
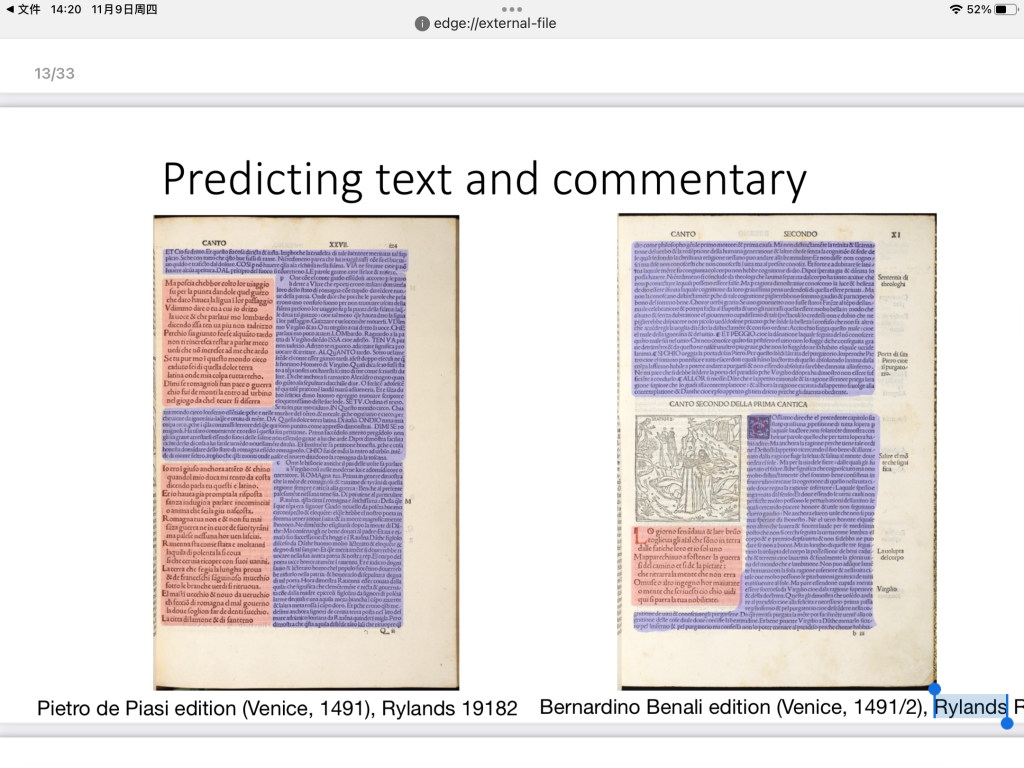
The most exciting part of the presentation was the image matching part. A database of all the data of thousands of books images are built and the researchers use the image searching engine (VGG VISE) to search a specific image in that database.

Finally, we came to the image comparison part. If people use their eyes to detect differences of two versions, sometimes it can be really hard if the pages are long and words are small just as the first picture shows. But now, we have the software in the link below to help us!https://www.robots.ox.ac.uk/~vgg/software/image-compare/

We tried using this image compare demo to find differences between similar images. Below are some examples of the images we took and compared.


This was a really useful session giving us an insight into technology that helps the development of digital humanities.