One Wednesday afternoon, Week 1 of Trinity term 2022, I was perusing through the Digital Bodleian database. Having finally set aside the time for Emma Huber’s Taylor Edition course, I was in search of a text to edit. When I first came across Douce MM 493, my interest was instantly piqued with its printed illustrations and hagiographical content, namely a Middle French ‘Life of Saint Margarete of Antioch’. However, as soon as I started scanning through the other folios, I very quickly found much more than Middle French. It contained folios in Middle English, Dutch, Latin and even some woodcuts cut out of an Early Modern Spanish text, and what ties them all together is their joint focus on St Margarete of Antioch. It was at that moment that I knew — this was the text for me.

Digital Humanities is an area of research which I have only recently discovered. In Oxford, we are quite fortunate to be in the company of many researchers who do use and lecture on digital techniques such as textual encoding, quantitative analysis, and stemmatics. Last year, I attended a ‘History of the Book’ digital launch which showcased the work of graduate students who had digitised their own selected texts, such as Philippe de Thaon’s Bestiary encoded in TEI P5 XML by Sebastian Dows-Miller (Oxford, Merton College Library, MS 249). (For more on this text, see Sebastian Dow-Miller’s post.) This was a truly eye-opening experience for me as Digital Humanities represented a way to merge my passion for language and literature with the mathematical side of me which I had left behind at A-level. After a discussion with Emma Huber, I knew this was an area I wanted to explore.
As two Oxford terms flew by, I felt the growing sense of urgency to start the course this Trinity term before the stress of fourth year, and now that I had finally found a suitable text, I felt more enthused than ever. To summarise briefly the main contents of the miscellany, I have laid them out as bullet points below:
- Front and rear endleaves: Two woodcuts of the life of St Margaret taken from Pedro de la Vega’s ‘Flos sanctorum’, Medina del Campo, 1578.
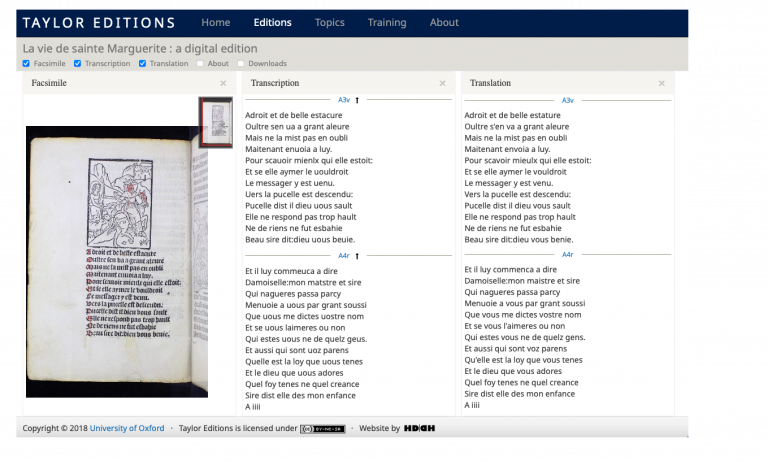
- ff. A2r – B8v: A printed Middle French ‘La Vie de sainte Marguerite’ from c.1495? with woodcuts throughout. It, however, is missing folio A8.
- ff. 2r – 5v: Folios 2 and 5 of a fragmentary printed Middle English ‘Life of Saint Margarete’, suggested to be from 1493.
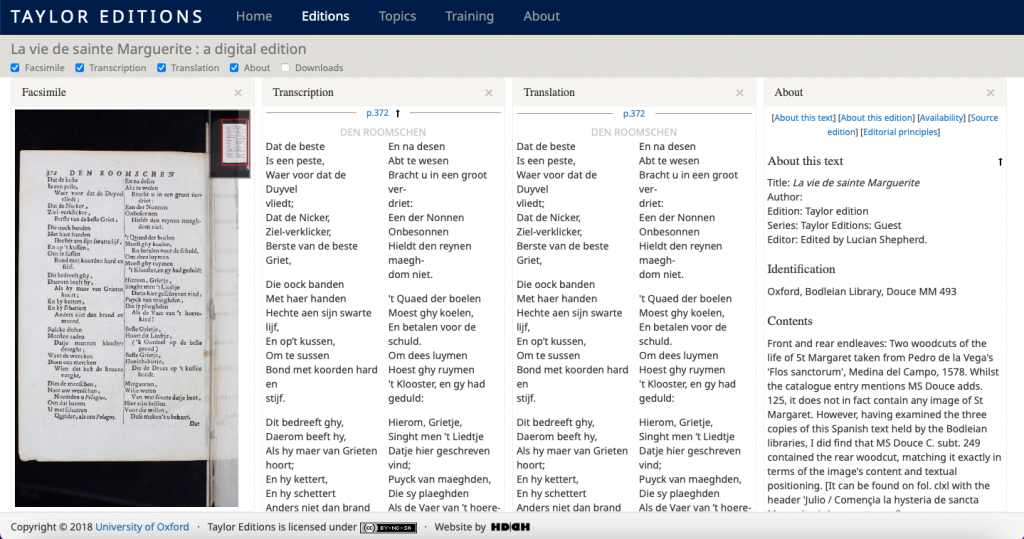
- pp. 369 – 372: Two folios from a Dutch book ‘Den Roomschen Uylen-Spiegel’, ed. J. Lydius (Dordrecht, 1671), containing a hymn for St Margaret in Latin and in Dutch.

The main reason for the eclectic nature of this miscellany is its collector, Francis Douce (1757–1834). Well known by archivists for perfecting the “cut-and-paste” technique, he often disassembled volumes and cut out woodcuts to be glued down in other copies or held in guard books for fragments. This can best be seen here with the front and rear woodcuts bound into the volume and on the lower flyleaf recto where you can see an image, the size of a stamp, glued on to the page. For more on Douce, see his entry in the Oxford Dictionary of National Biography.
When looking for a suitable text, I learned that there are a number of points which you should consider: Firstly, it should be of a suitable length to transcribe and encode over the time period of the project, in this case the eight weeks of an Oxford term. Secondly, it should be a manageable project with a clear plan from the start. You might think about whether you are going to transcribe the whole text or only an extract from it and which codicological features you are going to include, such as marginalia, shifting hands (i.e. scribes), and ownership inscriptions. Thirdly, you of course must consider any ethical and legal issues which may arise. For example, you should always doublecheck the copyright license of any text or photo you plan on using, as any derivative work, such as a digital critical edition, would still fall under the license’s jurisdiction. For this reason, I chose to work with a text held by the Bodleian libraries, which was out of copyright and already digitised so I did not need to worry about taking images of the volume myself either.
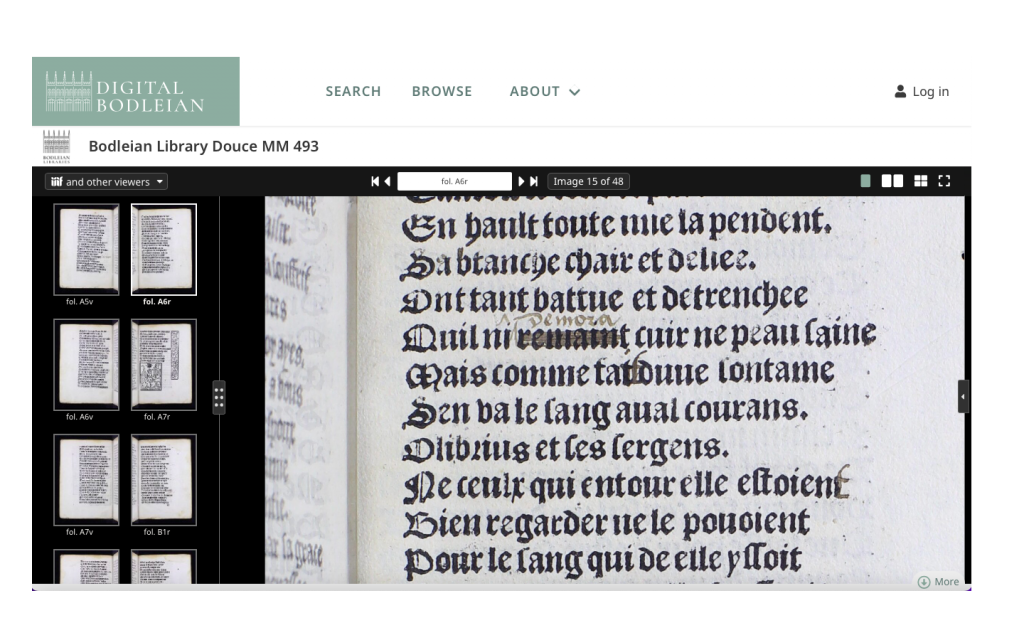
The second hurdle to overcome was how to transcribe the text. Transcription is when you record whatever is on the pages of a text, either very literally or with some leniency. I ended up choosing to make two transcriptions: one diplomatic which corresponded strongly with the text, and one standardised which I edited to make more readable and accessible. Thus, my edition could be used by an audience with a broader range of experience with Middle French. One particular advantage that this twofold approach had was that it highlighted common contemporary writing and printing practices, such as a lack of distinction between i’s and j’s, and u’s and v’s, and the frequent mixing up of u’s and n’s by the typesetter. For example, I struggled over the word ‘duue’ on fol. A6r (see the image above the title) which could be read as either ‘duve’ or ‘dune’, before realising that it was meant to be ‘d’une’. Whilst I did start transcribing entirely by “eye”, I discovered mid-way through Week 2 a platform called ‘Transkribus’ which uses Artificial Intelligence to recognise text and transcribe it. While a free version is accessible to anyone, you can also use pre-paid credits to train the software yourself to recognise a particular typeface or hand for a large corpus of texts, thus making it an effective time-saving tool for quantitative research. For MS Douce MM 493, its free AI models were very effective for the Middle English and Dutch parts, producing very few errors. Hence, I found the best approach to be a combination of the latest technology and a trained eye glancing from folio back to Word document.

Having completed both versions of my transcription and painstakingly perfected them under the guidance of Professor Daron Burrows and my dear friend, Michael Angerer, it was time to encode. Whilst I was certainly hesitant at first, I would say to any prospective course participants, “Don’t be so scared!” Following the TEI (Text Encoding Initiative) guidelines is not as complicated as you might think. TEI is a type of XML (Extensible Markup Language) used to describe our data (here: an early printed text transcription) which can then be read and interpreted by a computer. Through a set of guidelines agreed upon by the TEI community, a consistent standard can be adhered to with fixed meanings, as defined in the online guidelines. For example, the following line describes the catchword ‘Dat’ on p. 372 of MS Douce MM 493:
<fw type=”catch” place=”bottom-right”>Dat</fw>
<fw> is an element which stands for ‘forme work’ and describes headers, footers, catchwords, etc. The type attribute specifies the type of ‘forme work’ (here: a catchword) and the place attribute describes the location of the ‘forme work’ on the page. The marked-up XML document can then be transformed via XSLT (Extensible Stylesheet Language Transformations) into various other formats such as HTML for a webpage, PDF, or EPUB for a publication. For my project, TEI enabled the text to become a searchable critical edition as opposed to mere online facsimiles. Looking to the future, both the Middle French and Middle English verse narratives can now be used for linguistic analysis to compare with other versions of the ‘Life of Saint Margarete of Antioch’. In addition, this could further lead to stemmatological research where you examine the codicological relationships between the various versions in terms of time, language, and degree of influence, etc. Hence, textual encoding is just as important as transcription as it opens up new methodologies for research in the humanities.

Once the encoding was complete and I had checked through everything again, my digital edition was ready for publication. What at first seemed to be a challenging project was now a complete critical edition, free for anyone to access and use. Over the course of these eight weeks, I have even been fortunate enough to be able to examine my volume up close, see its beauty in real life and then try to highlight its most interesting features through digitisation. At times, this project has almost become like a detective game, questioning how accurate the catalogue entry is and hunting down other copies in Oxford for comparison (metadata can be found both in the entry for La vie de sainte Marguerite [French] and for The Life of St. Margaret [English verse]). For example, whilst the catalogue entry claims that the Spanish woodcuts are connected to MS Douce adds. 125, I can say with near absolute certainty that this is not true. Out of the three editions of Pedro de la Vega’s ‘Flos sanctorum’ held in the Bodleian Libraries (MS Douce C subt. 249, MS Douce adds. 125, and MS Balliol College Library, St Cross, 0550 e 05), only MS Douce C subt. 249 contains a printed illustration of St Margarete of Antioch which corresponds exactly with the rear endleaf woodcut (see above and the rear woodcut), thus proving that the woodcut was cut out from this version of ‘Flos sanctorum’. Through the Taylor Edition course, I have learnt a lot about the history of this miscellany: compiled in the 19th century, yet stretching from the late 15thcentury Middle French verses to the 19th century note on the upper flyleaf, and now available for all future students to read and admire for its eclectic nature.
To see my digital edition of MS Douce MM 493, click this link.
For more on the numerous ‘Vies de sainte Marguerite’, see their entry on ARLIMA (Archives de littérature du Moyen Âge)
For more on the Middle English ‘Life of Saint Margaret’, see the catalogue entry and this entry in the Digital Index of Middle English Verse. I also later found a transcription from the University of Otago with some interesting metadata.
Lucian Shepherd is a 2nd year undergraduate student at Oriel College, University of Oxford . He studies Modern Languages (French and German) and is hoping to pursue a career in academia in the future.