
UNIQ+ is a series of research internships designed to give excellent experience to students from under-represented backgrounds to enrich future applications for postgraduate study or graduate employment. For the History of The Book, we are particularly looking at enhancing digital research skills and exploring books as cultural objects. These skills will then be used for a collaborative group project based on the Treasures of the Taylorian.
After an intense (but equally rewarding) week of learning R, I was ready to quit this foreign realm of statistics and return to the more familiar field of humanities. That is, the digital humanities.
If the last year has illuminated anything to me, then it is that digital resources are more crucial than ever. All my education this year has been conducted online via many video calls – much like this present internship. And whilst I was familiar with digital resources, I have most probably spent more time these past twelve months trawling through online library databases than I have in any physical counterpart. Consequently, the opportunity to participate in this project, and contribute to the digitisation of centuries-old texts, is compelling.
But how do we obtain a digital edition of a physical text?
On the Friday of week one, we had our first introduction to Digital Editions and text encoding with Emma Huber. This presentation was as fascinating as it was informative. Emma provided a great insight into transcription (and what to consider beforehand, such as readership and the aim of the text), TEI, and some of the reasons for digital preservation.
Come Monday morning, and our first code-a-thon with Mary Newman and Sebastian Dows-Miller, we were able to apply what we had learned on Friday to the daunting task that lay ahead: encoding some deletion poetry by Ronald Johnson. Having never before used, or even heard of Oxygen XML Editor (the software we used to encode our texts), I might have felt a little thrown in the deep end, were it not for the wonderful guidance of Mary and Seb. They helped set us up with a TEI header and some useful element tags – <l>, <hi>, and <del> – to tackle this poem. We were equally apprised of author view, which enabled us to see how our code represented the poem. This function really helps to visualise what our code does.
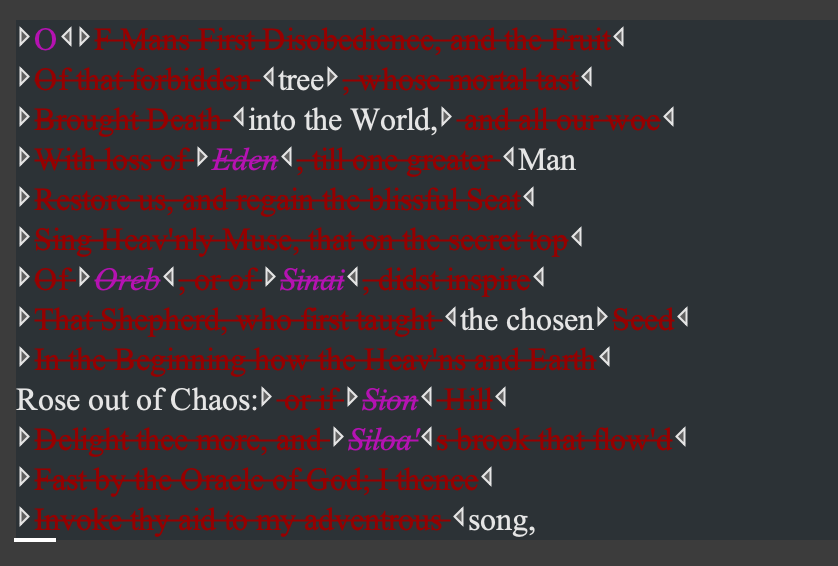
On Tuesday, being a great deal more proficient in TEI and xml than the day before, we were ready for some more fun encoding challenges. So why not head straight for the belly of the beast? We divided the first four folios of ‘Goostly psalmes and spirituall songes’ (one of the seven constitutive pamphlets of the sammelband we aim to transcribe and encode during this internship) between the four of us and set to work! With the knowledge and skills that we had acquired so far, we each made our best attempts to transcribe and encode this text.
To break down this task into more manageable chunks, we first considered what sort of approach we would use for our transcriptions – I opted for a very diplomatic approach and chose to include all of the punctuation and diacritical marks as they appeared. With this transcription, I then created an xml document and started to encode it. Encoding the text was not as daunting as I had imagined, instead I found it somewhat therapeutic; nesting different element tags within each other is not dissimilar to assembling a Russian doll. The whole process was also facilitated by the sessions provided by Mary and Seb, who covered how to encode some more tricky features, such as marginalia, and generally answer any queries that we had. Equally, it was useful to refer to the existing Digital Editions on the Taylor Editions website to see how other students had handled details similar to those in our pamphlet.

Composing stick 
Goostly psalmes and spirituall songes
On Thursday afternoon, we were fortunate enough to have a session with Richard Lawrence in the Bodleian Bibliographical Press. During the session, Henrike, Seb, and Richard successfully printed the title of the pamphlet we had been encoding: “Goostly psalmes and spirituall songes”. Whilst it was a shame that we could not all be there in person, it was incredibly fascinating to watch and learn how pamphlets were printed. It was particularly interesting to learn that type is set backwards, from right to left, as the press produces a mirror image. Moreover, the act of carefully selecting each character and the precision needed for typesetting in general drew strong comparisons for me with using TEI to create a digital edition of a text; text being incorrectly spelt, or the type slipping, is comparable perhaps to forgetting to close a tag, or having a validation error. The attention to detail required is consistent.
This second week of our UNIQ+ internship has been incredibly instructive and enjoyable and leaves me excited for what lies ahead in the coming weeks!
Freya Mugford is one of this year’s UNIQ+ interns with the History of The Book. She studies English and French at the University of Exeter. She is very excited to share her passion for research with Oxford University, and is looking forward to hopefully writing more blogs over the coming weeks!
1 thought on “UNIQ+ Week 2: Learning to encode using TEI”